
Illustration by Somnath Bhatt
The exclusionary costs of large-scale computing
A guest post by David M. Liu and Sarah Sakha. David is a computer science Ph.D. student in Khoury College at Northeastern University. Sarah is a Humanitarian Policy and Advocacy Officer at the International Rescue Committee (IRC).
This essay is part of our ongoing “AI Lexicon” project, a call for contributions to generate alternate narratives, positionalities, and understandings to the better known and widely circulated ways of talking about AI.
The increasing emphasis and reliance on specialized, high-performance computational resources in AI research threaten to deepen power imbalances. To explore this issue, we examined the growing proportion of research papers published in AI’s top conferences that utilize graphics processing units (GPUs). This high-performance hardware is expensive for some, and simply impossible to obtain for others. The success of big-data applications and blackbox architectures¹ has galvanized a computational arms race that simply bolsters barriers to the field. We argue that while the AI ethics discourse has focused on transparency, it has been too slow to engage with these material questions of who can access or afford computational resources. “Power” captures both the energy needed to sustain modern AI research, as well as the gross accumulation of influence in the hands of the few.
Notable studies have already measured the environmental impact of large-scale AI² and even shown that, despite their cost, these large models do not always perform well.³ More recently, the paper coining the term “Foundation Models” rightfully points to the dangers of concentration of power in the case of unprecedentedly large models, such as GPT-3 and BERT.⁴ We zero in on the specific issue of reliance on GPU hardware in academic AI research. While Ahmed and Wahed similarly point to the rise of large computing in AI research,⁵ they go on to encourage greater use of computational equipment. Our aim is to question what we are using AI for in the first place — and how that can inform approaches to “democratizing” AI.
Survival of the Fittest: AI’s increasing reliance on Graphics Processor Units (GPUs)
The increasing use of GPUs in AI research points toward an escalating “arms race” within the field. GPUs are high-performance hardware that can train and run AI models efficiently, but also can be costly — both in terms of money and energy expended.⁶ The prevalence of GPUs in academic research is an effective unit of analysis because for those at large technology companies and elite universities, GPUs are easily accessible, but for most others, the same hardware can be impossible to obtain, which we later detail. To quantify AI’s increasing and excessive reliance on large computational resources, we analyzed all papers (over 15,000) published in the last decade at three of AI’s largest conferences: Conference on Neural Information Processing Systems (NeurIPS), International Conference on Machine Learning (ICML), and International Joint Conference on Artificial Intelligence (IJCAI).⁷ At these three conferences, it is customary and recommended for authors to specify their computing environment, often in the experiments or supplemental information section. For instance, a paper may state, “All of the experiments in this paper were conducted on an NVIDIA Titan Xp GPU.”
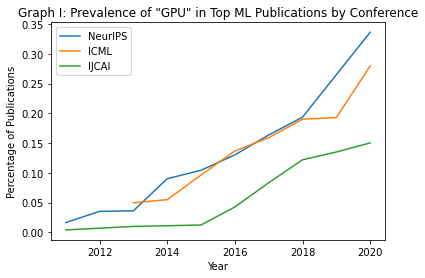
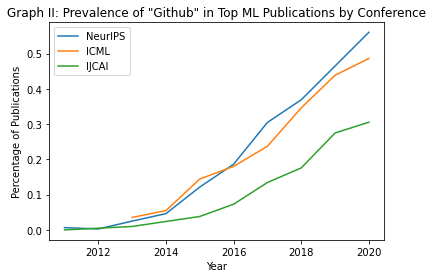
Across the 15,000-plus articles, we tracked usage of the keywords “GPU” and “Github,” which often signifies access to open-source code. In Graph 1, we demonstrate that across all three conferences, an increasing number of papers are specifying usage of GPUs; for instance, in 2011, fewer than five percent of papers published at NeurIPS mentioned GPUs, whereas in 2020, over 30 percent of papers at the same conference mentioned GPUs. We also counted the number of papers that included a Github link; per Graph 2, an increasing number of papers include links to source code, which is encouraging in terms of transparency. However, increased dependence on specialized hardware shows that source code may be of limited use if other researchers lack access to the same hardware, presenting challenges to reproducibility.
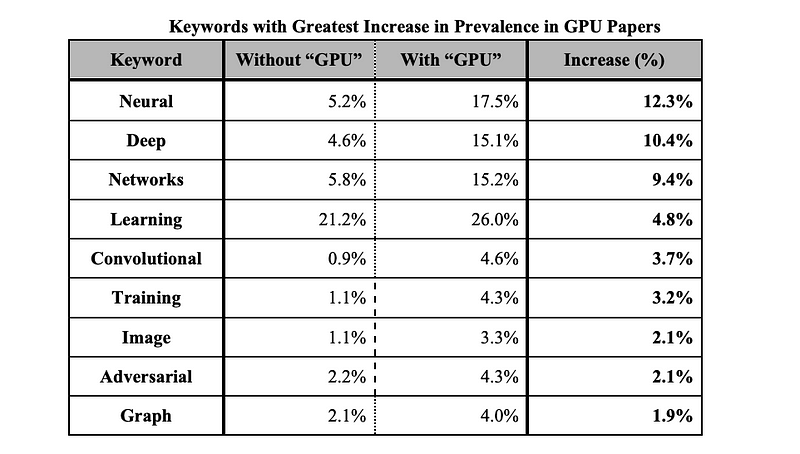
In order to explore the drivers of this so-called arms race, and the possible applications of GPUs, we analyzed titles from papers that specified a GPU and those that did not, and then measured the prevalence of various keywords. The table below lists keywords with the greatest increase in usage in GPU papers. Keywords such as “Neural [Networks],” “Deep [Learning],” and “Convolutional” suggest that GPU papers typically feature more advanced architectures and complex models; on the other hand, keywords such as “Image” and “Graph” reflect the field’s increased focus on image processing and graph analytics, both of which are data-intensive. We interpret this data to suggest that the rise in use of GPUs is not just because conference standards require specifying computing environments, but also because the underlying topics of interest fuel the need for higher computing power.
The rise in usage of high-performance computing in AI is the product of the increasing necessity of this hardware to be able to conduct the type of research expected in certain subfields. For instance, fields such as computer vision, natural language processing, and graph machine learning often expect researchers to test new methods on existing benchmark datasets; however, the benchmark datasets in each of these disciplines, such as the “Colossal Clean Crawled Corpus,” ImageNet, and MAG-Scholar can be hundreds of gigabytes in size, which can be exceedingly difficult to process without a GPU’s parallel efficiency. While it is useful to standardize methods, especially given the number of new methods proposed annually, the standardization also creates a barrier to entry for researchers to contribute to AI.
Bridging the computing divide: Unequal distribution of power
Access to computing power disproportionately restricts people of color, people from and living in the Global South, and people from lower socioeconomic backgrounds. The increased reliance on high-powered machines also leads to negative environmental consequences, which disproportionately impacts non-Western countries. To illustrate this point, we expanded our research to center the voices of researchers who could directly attest to the consequent power imbalance, including impacted researchers of color and from Global South contexts, largely through our own personal and professional networks.
Roya Pakzad, the founder of Taraaz, a research and advocacy organization working at the intersection of technology and human rights, spoke with us about how her sister who lives in Iran had asked to buy her a good GPU. Because of technological sanctions on Iran, her sister cannot purchase or access hardware. Even the few GPUs available in Iran are extremely expensive and usually not up-to-date models; some others cannot be purchased with an Iranian credit card.
Roya and her sister are just one example in a web of complex technological sanctions against Iran. For example, due to the ambiguity of U.S. sanctions and the agency that grants tech companies, Iranians cannot access global cloud services, Github’s premium features, and app marketplaces (such as the Apple App Store). And Iran is just one example of unequal access to technology, and how access to specifically GPUs bolsters barriers to the field. The supply of GPUs goes overwhelmingly to rich, Western countries, with the recent cryptocurrency and scalper-induced global shortage exacerbating issues of access.⁸ Demonstrably, GPUs preclude the democratization of AI. As Pakzad pointed out, this inequitable distribution has led to a concentration of research — and power — in the hands of a few powerful tech companies, and this disparity affords them an unchecked voice in the research, policy, and tech community.
While many tech companies are investing ways to mitigate carbon emissions, the development of massive language and computer vision models and their associated emissions works starkly against those efforts. Emma Strubell, an assistant professor of computer science at Carnegie Mellon University, has measured the power consumption of modern natural language processing models and found that training the well-known BERT model emits nearly the same amount of carbon as a flight from New York to San Francisco.⁹ We interviewed her as a part of this project, and she attested to how reducing our carbon footprint is a critical entry point, given that it is easier to quantify. However, she argues, “The bigger issue about these large models is the lack of access and sort of consolidation of power.” And ultimately, it is that imbalance in power that engenders disproportionate impacts on the climate and environment.
Walking on [algorithmic] eggshells: Does the solution actually lie inside the field?
Mitigating carbon emissions and requiring impact statements from researchers — as was the case at NeurIPS 2020 — are important first steps to increasing equity, accessibility, and transparency. That being said, Strubell and Pakzad noted pushback to carbon emissions reporting and broader impact statements, citing fears of regulatory practices (e.g., the requirement of impact statements) being more prescriptive than productive. Other tangible efforts to increase accessibility center around better and more equitable access to education. Nabil Hassein, a technologist, educator, and activist, spoke to us about how programming education is a critical barrier to access, and highlighted race and class as crucial areas of study to explore who has access to this education in the first place.
To bridge disparities in access and rectify power imbalances, we need to fundamentally re-envision what we are doing with AI. Initiatives such as the National Research Cloud, which aims to make access to high-performance hardware more affordable and accessible; AI 4 All, which has increased access to computer science education to historically underrepresented groups; and Black in AI, which has increased the presence of Black people namely at AI conferences, have lowered the barriers to entry and innovation in the field. While these initiatives benefit the communities that have been marginalized and even hurt by AI, we argue that we should be cautious that the ways we approach democratizing and diversifying AI do not further reinforce a need for and reliance upon particular hardware or platforms to succeed in the field. We should question whether we are sharing resources, capacity, and thus power to enable and empower people to use AI however they want — or simply in the ways set forth by the Global North. Democratization should not necessarily mean universal access to using physical resources, but access to deriving the same benefits of those resources, which entails both the equal ability to innovate and to mitigate risk and harm through “innovation.”
Diversifying AI requires a more holistic understanding of AI — by examining AI from diverse disciplines and voices from outside the field to encourage a wider public understanding of AI, its applications across different fields, and its societal impact. Roya Pakzad spoke to a lack of storytelling in the field, and a “lack of connection to real-world examples.” And as such, she always tries to incorporate her own stories into her work. For example, one of her research papers looks at the role of Information and Communication Technologies (ICTs) in improving refugees’ livelihoods. In the preface of that paper, she begins by talking about her own story — as an immigrant who left her home but still has one — and how that connects her to the experiences of many refugees and motivates her research.
Maya Ganesh, a researcher focusing on the intersection of technology, digital culture, and society, spoke at length about the very specific and narrow ways AI is being talked about. Her work challenges not only how we understand AI, but how we understand humans and society as a whole. Her project, “A is for Another: A Dictionary of AI,” questions what it means to be human and non-human in the face of AI. Her work on AI as a metaphor — beyond the realm of computation — builds off the universality of the metaphor and of using metaphors to explain and understand the world around us, such as for people outside of the tech space to understand AI.
At AI’s conferences, addressing global barriers to access goes beyond any single individual or paper; improving accessibility requires a systematic and cultural shift. We believe that by shedding light on the environmental harms and exclusionary costs of large-scale computing, we can help advance the conversation. While exciting frontiers for AI discovery and applications remain, we cannot fall into the trap of pursuing accuracy at any and all costs; instead, we need to approach our use of hardware with greater scrutiny of our own footprint — and of how we conceive of power and access in AI for all of us.
References:
[1] C. Rudin and J. Radin, “Why Are We Using Black Box Models in AI When We Don’t Need To? A Lesson From An Explainable AI Competition,” Harvard Data Science Review, vol. 1, no. 2, Nov. 2019, doi: 10.1162/99608f92.5a8a3a3d.
[2] E. Strubell, A. Ganesh, and A. McCallum, “Energy and Policy Considerations for Modern Deep Learning Research”, AAAI, vol. 34, no. 09, pp. 13693–13696, Apr. 2020.
[3] E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell, “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?,” in Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, New York, NY, USA, 2021, pp. 610–623. doi: 10.1145/3442188.3445922.
[4] R. Bommasani et al., “On the Opportunities and Risks of Foundation Models,” arXiv:2108.07258 [cs], Aug. 2021, Accessed: Aug. 30, 2021. [Online]. Available: http://arxiv.org/abs/2108.07258
[5] N. Ahmed and M. Wahed, “The De-democratization of AI: Deep Learning and the Compute Divide in Artificial Intelligence Research,” arXiv:2010.15581 [cs], Oct. 2020, Accessed: Aug. 30, 2021. [Online]. Available: http://arxiv.org/abs/2010.15581
[6] GPU prices range from a few hundred dollars to upwards of ten thousand.
[7] The code and documentation needed to replicate our results is included at https://github.com/dliu18/ai-lexicon-gpu
[8] “Inside the GPU Shortage: Why You Still Can’t Buy a Graphics Card,” PCMAG. https://www.pcmag.com/news/inside-the-gpu-shortage-why-you-still-cant-buy-a-graphics-card (accessed Sep. 09, 2021).
[9] E. Strubell et al. See Note 2.
Related Reading
See all




1. AI and Tech Industrial Policy: From Post-Cold War Post-Industrialism to Post-Neoliberal Re-Industrialization
Susannah Glickman
Mar 12, 2024

2. A Modern Industrial Strategy for AI?: Interrogating the US Approach
Amba Kak & Sarah Myers West
Mar 12, 2024
